12. 训练模型
超参数
定义模型之后,下一步是用超参数实例化模型。
# Instantiate the model w/ hyperparams
vocab_size = len(vocab_to_int)+1 # +1 for the 0 padding + our word tokens
output_size = 1
embedding_dim = 400
hidden_dim = 256
n_layers = 2
net = SentimentRNN(vocab_size, output_size, embedding_dim, hidden_dim, n_layers)
print(net)步骤和之前差不多,但是要注意 vocab_size。
它等于 vocab_to_int 字典的长度(所有唯一字词数量)加一,因为我们在填充输入特征时添加了标记 0。预处理数据之后,这个超参数需要再加上一两个额外的特殊标记。
将 output_size 设为 1,输出将是一个 0-1 之间的 S 型函数值,表示影评是正面还是负面影评。
然后是嵌入和隐藏维度。嵌入维度只能代表 70000 个字词的一小部分,200-500 之间的任何一个值都行。我选择的是 400。同理,对于隐藏维度,256 个隐藏特征应该足够区分正面和负面影评了。
我将创建两个 LSTM 层级。最后实例化模型并输出模型,看看一切是否正常。
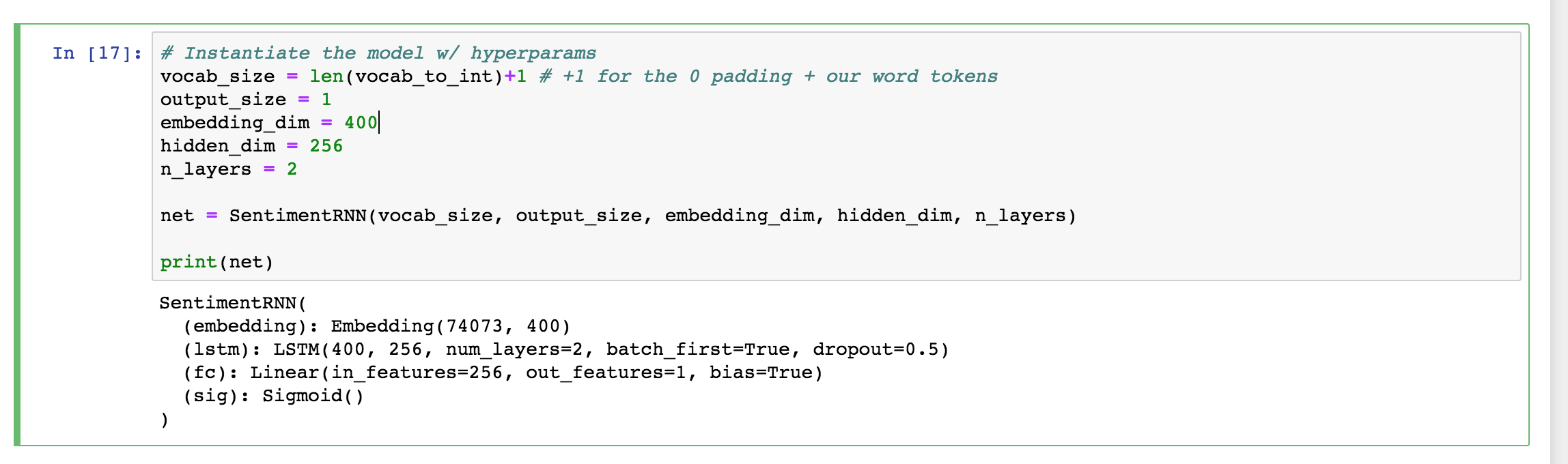
模型超参数
训练和优化
训练代码应该看起来很熟悉了。不过有一个不同之处:我们将使用适合单个 S 型函数输出的新交叉熵损失。
BCELoss(二元交叉熵损失)会对 0-1 之间的单个值应用交叉熵损失。
同样使用 Adam 优化器。
# loss and optimization functions
lr=0.001
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)输出,目标格式
另外请注意,在训练循环里,我们通过运行 output.squeeze() 使输出没有空维度,并且通过 labels.float() 将标签设为浮点数张量。然后执行反向传播步骤。
训练和评估模式
从下面可以看出,当我们用数据训练模型时和用数据评估模型时,会在训练模式和评估模式之间切换。
训练循环
下面是一个常见的训练循环。
我将只训练 4 个周期,因为我发现 4 个周期后验证损失停止下降了。
- 先初始化隐藏状态,然后进入批次循环,接着将隐藏状态与其历史记录分离,并执行反向传播步骤。
- 从 train_dataloader 中获取输入和标签数据。然后将模型应用到输入上并比较输出和真实标签。
- 我还添加了一些检查模型在验证集上效果的代码,通过这些代码可以判断何时停止训练或哪个模型效果最好,值得保存下来。
# training params
epochs = 4 # 3-4 is approx where I noticed the validation loss stop decreasing
counter = 0
print_every = 100
clip=5 # gradient clipping
# move model to GPU, if available
if(train_on_gpu):
net.cuda()
net.train()
# train for some number of epochs
for e in range(epochs):
# initialize hidden state
h = net.init_hidden(batch_size)
# batch loop
for inputs, labels in train_loader:
counter += 1
if(train_on_gpu):
inputs, labels = inputs.cuda(), labels.cuda()
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
h = tuple([each.data for each in h])
# zero accumulated gradients
net.zero_grad()
# get the output from the model
output, h = net(inputs, h)
# calculate the loss and perform backprop
loss = criterion(output.squeeze(), labels.float())
loss.backward()
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
nn.utils.clip_grad_norm_(net.parameters(), clip)
optimizer.step()
# loss stats
if counter % print_every == 0:
# Get validation loss
val_h = net.init_hidden(batch_size)
val_losses = []
net.eval()
for inputs, labels in valid_loader:
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
val_h = tuple([each.data for each in val_h])
if(train_on_gpu):
inputs, labels = inputs.cuda(), labels.cuda()
output, val_h = net(inputs, val_h)
val_loss = criterion(output.squeeze(), labels.float())
val_losses.append(val_loss.item())
net.train()
print("Epoch: {}/{}...".format(e+1, epochs),
"Step: {}...".format(counter),
"Loss: {:.6f}...".format(loss.item()),
"Val Loss: {:.6f}".format(np.mean(val_losses)))一定要看看训练损失和验证损失在训练过程中是如何降低的。对训练过的模型满意后,可以通过多种方式测试模型,看看模型在新数据上表现如何。
查看 Solution 代码
要仔细查看 solution 代码,请转到 solution workspace 或点击此处查看网页版。